Our School is an internationally recognised hub for teaching and research in modern European languages and cultures, and in Linguistics, Applied Linguistics, English as a Second Language and Language Testing.
Discipline areas

Languages
Our Language programs combine best practice in learning languages at all levels with leading research in key areas for deeper cultural understanding and communication. We work closely with other programs in the Faculty of Arts and the rest of the University to connect languages into all degrees via breadth or the Diploma of Languages.
Linguistics and Applied Linguistics
Our linguistics focus promotes working together in language teaching, learning and assessment strategies, drawing on the expertise of our Linguistics and Applied Linguistics discipline area and our research centres and units. We also provide a focal point for reflection and research in all areas of linguistics, and in the interface between language and culture.
Our discipline areas are:

Explore our stories, news and events
Learn about our research centres, hubs and units
- Language Testing Research Centre (LTRC)
The LTRC at the University of Melbourne has become an international leader in research and development in language assessment and language program evaluation. - Research Hub for Language in Forensic Evidence
We serve as a national hub coordinating research involving linguistics, law, and law enforcement. - Research Unit for Indigenous Language (RUIL)
RUIL works with Indigenous communities across Australia and the region to expand and strengthen Indigenous language research. - Research Unit for Multilingualism and Cross-Cultural Communication (RUMACCC)
RUMACCC conducts research in Australian and international contexts into all aspects of the maintenance and development of bi- and multilingualism.
Resources
-
Horwood Recording Studio
Need to record interviews or voiceover work? Find out more about hiring our studio. The aim of the Horwood recording studio is to make sure that you can record in a fun and relaxed atmosphere. No matter what your idea, please contact us to see how we can assist you.
-
Language Placement Testing
Enrolling in a language subject for the first time? Take our online test first to help determine which level is suitable for you.
-
The Secret Life of Language
The Secret Life of Language is a podcast series from the studios of the School of Languages and Linguistics. In the podcasts we dive into the cultures, arts and histories that underpin and inform the world's diverse languages.
-
VCE kits
Studying or teaching VCE German or Italian? Purchase our kits to help prepare for VCE exams.
-
English as a Second Language (ESL)
Established in 1992, our program was one of the first in Australia to offer a range of credit-bearing ESL subjects.
-
European Studies
European Studies is an interdisciplinary program exploring the cultures, societies and languages of Europe.
-
French Studies
One of the first subjects taught at the University of Melbourne, our French program offers world-class research and teaching in French language and literature studies.
-
German Studies
German Studies has a strong reputation in both teaching and research, and an impressive publishing record over a broad range of topics.
-
Gender Studies
Our program explores the significance of gender and sexuality on a range of discourses embedded within culture, identity and global history.
-
Italian Studies
Among the leading programs of its kind in Australia, Italian Studies at the University of Melbourne is also one of the longest running.
-
Linguistics and Applied Linguistics
Our Linguistics and Applied Linguistics program is #1 in Australia and #26 in the world (QS rankings 2023).
-
Russian Studies
Part of Australia’s #1 University for Modern Languages (QS World University Rankings by Subject 2021), we offer a full graduate (Masters and PhD) and undergraduate (Major) program in Russian Studies
-
Spanish and Latin American Studies
Our program offers opportunities to study and undertake independent research projects with innovative scholars working in areas such as Spanish and Latin American cinema, Latin American popular culture studies, Latin American popular music, and research with Indigenous and Afro-Latin communities.
The School of Languages and Linguistics is an internationally recognised hub for research in modern European languages and cultures, and in Linguistics, Applied Linguistics, English as a Second Language and Language Testing.
Research projects
Explore a selection of Australian Research Council-funded and other research projects undertaken by academics at the School of Languages and Linguistics.
-
Who is Nature?
Professor Adrian Hearn and Dr Steve Kelly have created a 360-degree interactive film invites you on a journey to five Latin American and Australian sites of ceremonial exchange with nature.
-
Visual evidence: transforming modern sex research (1880s-1930s)
This project explores how visual evidence became a central means of communicating scientific and medical knowledge about human sexuality in an era of rapid technological change in the German-speaking world.
-
French Wine Culture
Analysing wine as a product of regional, national and international geopolitics, Associate Professor Jacqueline Dutton shows that wine is so much more than fermented grape juice, especially for the French.
-
Trust and Cultural Exchange
The Trust and Cultural Exchange project brings together 15 academics from a variety of Schools and Faculties to explore theory and practices of trust across history and cultures.
-
Aboriginal language use in Darwin
Dr John Mansfield investigates how highly complex Aboriginal languages, traditionally spoken by small semi-nomadic clan groups, are used in an urban context.
-
Language placement test review
The study focuses on the multi-method evaluation of a suite of language placement tests for seven languages embedded in an institutional policy.
-
50 words project
This project aims to provide fifty words in every Indigenous language of Australia. We hope this will be a useful resource for schools and educational organisations, and for the general public to discover the diversity of languages around Australia.
-
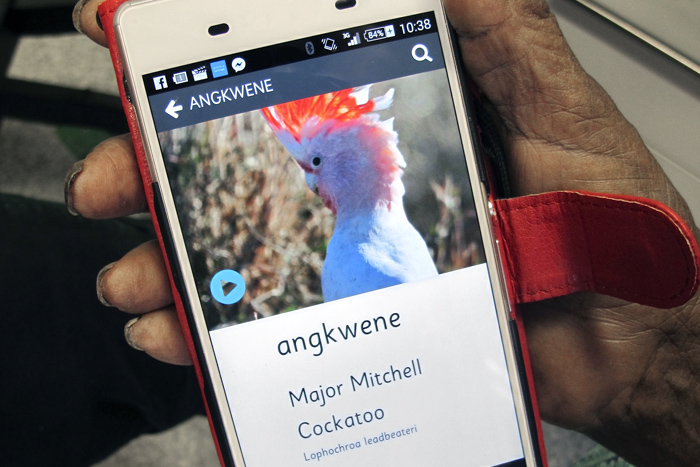
Getting in Touch: Bird app development
The Getting in Touch bird apps enable people to listen to recordings of language names for birds alongside photographs of birds and the sounds of their calls.
Research centres, hubs and units
The School of Languages and Linguistics hosts the Melbourne node of the Australian Research Council Centre of Excellence for the Dynamics of Language, the Language Testing Research Centre, two research units: the Research Unit for Indigenous Language and the Research Unit for Multilingualism and Cross-Cultural Communication, and the Research Hub for Language in Forensic Evidence.
-
ARC Centre of Excellence for the Dynamics of Language
We investigate how languages vary and evolve, and how we learn and process them. By understanding why the world's languages are designed so differently, we hope to generate scientific insights and exciting new technologies.
-
Language Testing Research Centre
We're international leaders in the research and development of language assessment and language program evaluation. Established in 1990, we've worked on many major projects for institutions and government agencies throughout the world.
-
Research Unit for Indigenous Language
We work with Indigenous communities across Australia and the region to expand and strengthen Indigenous Language research, and to support efforts by communities to maintain their linguistic and cultural heritage.
-
Research Hub for Language in Forensic Evidence
We serve as a national hub coordinating research involving linguistics, law, and law enforcement. Our aim is to assist the courts in ensuring that language & speech in forensic evidence is used in the interests of justice and fairness.
-
Research Unit for Multilingualism and Cross-Cultural Communications
We research bilingualism and multilingualism, and share our findings with the community via regular free workshops for parents, teachers and others interested in bilingual education.
Explore more
-
Research publications
This section contains a selective list of recent major publications (books and book chapters) in all our programs within The School of Languages and Linguistics.
-
Discussion groups
Learn about our discussion groups on Conversation Analysis and Phonetics and Phonology.
-
Research strengths
We conducts research into a wide range of language practices, covering through its subjects a diversity of times, places and themes which reflect the latest developments in language and linguistic practice.
Partner with us
The School welcomes research collaboration. Contact us to learn more about partnering with the School of Languages and Linguistics.
-
Undergraduate
Information for current undergraduate students including policies, assessment and contact information.
-
Honours
Honours provides scope to refine your analytical skills and research techniques while significantly enhancing your range of options after graduation.
-
Graduate studies
Information for current graduate coursework students.
-
Graduate research
Information for prospective students and those currently enrolled in a PhD or Masters by Research program.
-
Outbound Exchange
The Exchange program allows students to study at an overseas institution through the University's Exchange or Fee-paying programs.
-
Language Exchange Club
Any student studying a language is welcome to join the program and converse with a native speaker. Come here to make friends, international contacts and improve you language skills naturally!
-
Horwood Recording Studio
Need to record interviews or voiceover work? Find out more about hiring our studio. The aim of the Horwood recording studio is to make sure that you can record in a fun and relaxed atmosphere. No matter what your idea, please contact us to see how we can assist you.
-
Language Placement Testing
Enrolling in a language subject for the first time? Take our online test first to help determine which level is suitable for you.
-
The Secret Life of Language
The Secret Life of Language is a podcast series from the studios of the School of Languages and Linguistics. In the podcasts we dive into the cultures, arts and histories that underpin and inform the world's diverse languages.
-
VCE kits
Studying or teaching VCE German or Italian? Purchase our kits to help prepare for VCE exams.